これもコードを動かしながらおぼろげに理解をして行っているところ。
印象的であったのは、4章の二次関数予測が隠れ層あり、活性化関数ありでうまく行えているところ。そして関数を三次関数にしたり三角関数にしたりしても予測ができるのだ。例えば、最初のデータを
# 訓練データ、検証データの計算
np.random.seed(123)
x = np.random.rand(1000,1)*10-5
y =3*np.sin(2*x) + np.random.randn(1000,1) * 0.1
# データを500件ずつに分け、それぞれ訓練用、検証用とする
x_train = x[:500,:]
x_test = x[500:,:]
y_train = y[:500,:]
y_test = y[500:,:]
のように生成すると、そのプロットが下記のようになり、
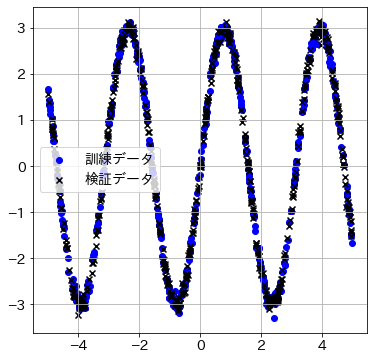
これを隠れ層・活性化関数ありにしてパラメータを学習させると、
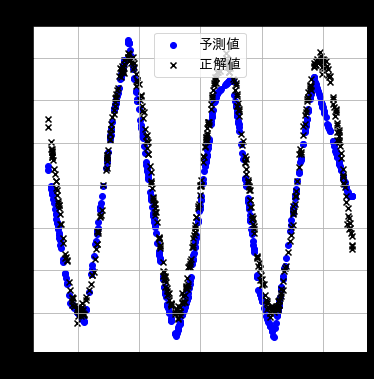
と複雑なデータもよく学習できていることが分かる。さらに学習回数を一桁増やして10万回にすると、
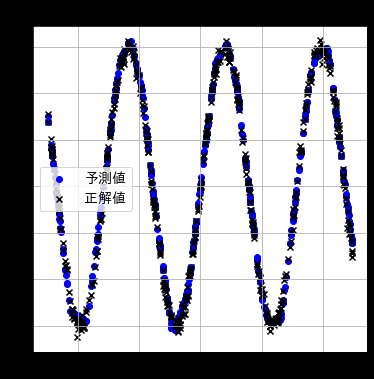
ほぼsin関数をなぞるまでになる。なるほど、これはすごいや。
というのは、通常の線形回帰は文字通り直線しか回帰できない。そして例えばデータを見ると二次関数に近そうだと思えば、それを前提にした式を作った上で回帰計算を行い、二次関数のパラメータ(ax^2+bx+cのa, b, c)を求めていく必要がある。
ところが、深層学習を手法として使うと予め数学的な関数を定めずともデータにフィットするパラメータが求まったのだ。もちろん、実際には学習率等をうまくチューニングしないと効率よくは学習できない、つまり手動の部分が完全になくなるわけではないのだけれど、従来型の統計手法で回帰計算を行うのに比較すると格段に上等になった感じだ。